把 VPS 运维从公网收口到内网:一套可复制的思路(Tailscale + 统一账号 + 最小暴露面)

我曾有台 VPS 被入侵后用于 DDoS 攻击,导致严重后果,促使我重新审视自己的运维模式。这篇文章记录了我如何把 VPS 运维入口从公网迁移到 Tailscale 搭建的私有内网,通过统一账号管理、最小暴露面的安全策略,以及明确的资产清单,让安全变成默认设置,而不是靠自律和记忆。现在我能更放心地管理所有服务器,减少了运维焦虑,也降低了安全风险。
目录
我手里有一批 VPS,分布在不同国家、不同商家、不同用途。机器一多,“运维方式”如果不统一,最后一定会变成两种状态:要么你被安全焦虑折磨,要么你被维护成本折磨(通常两者一起)。
写这篇文章的起因,是我亲身经历过一次惨痛的教训:
我有一台 VPS 曾经被入侵,当时直接变成了肉鸡,用来进行 DDoS 攻击,结果商家投诉邮件直接飞到我的邮箱里。收到邮件后,我赶紧重装系统,还特别谨慎地开启了仅密钥登录、换成高位SSH端口、配置好 fail2ban,当时心想“这下万无一失了吧”。
万万没想到,没过几天,这台机器又被投诉了。我怀疑可能是重新装了一个带漏洞的 Next.js 项目,或者是代理端口密码被复用了,但根本没机会再去验证——因为一周之内连续两次被投诉违反了商家的 AUP,这台 VPS 直接就被删了。
痛定思痛之后,我决定彻底调整运维策略,认真做一次真正的安全收口。
一、真实痛点是什么
当 VPS 数量上来以后,问题并不是“某台机器怎么配”,而是:
• 公网 SSH/RDP 暴露在外,扫描、撞库、噪音日志不断
• 不同机器有不同账号、不同端口、不同安全策略
• 你很难“确认现在到底安全吗”,只能“希望自己没忘记关某个口子”
• 你想做自动化(巡检/批量更新/统一加固)但每台都不一致,脚本写不下去
最终你会发现:真正需要治理的是“运维平面(management plane)”,而不是某台机器本身。
二、我的目标:把“安全”变成默认行为
我给自己定了一个非常具体、可验证的目标:
- 所有 VPS 运维入口统一:svc + SSH key(没有密码登录)
- 运维入口默认不走公网:只允许从内网(Tailscale 100.x)访问
- 机器要有“身份”:用 tags/role 标注用途(edge/app/transit)
- 有一份资产清单作为事实来源:主机名、用途、公网 IP、Tailscale IP、角色、标签
注意:这里的关键不是“我用了什么工具”,而是我把‘可控边界’从公网搬到了内网,并且把“收口”做成默认动作。
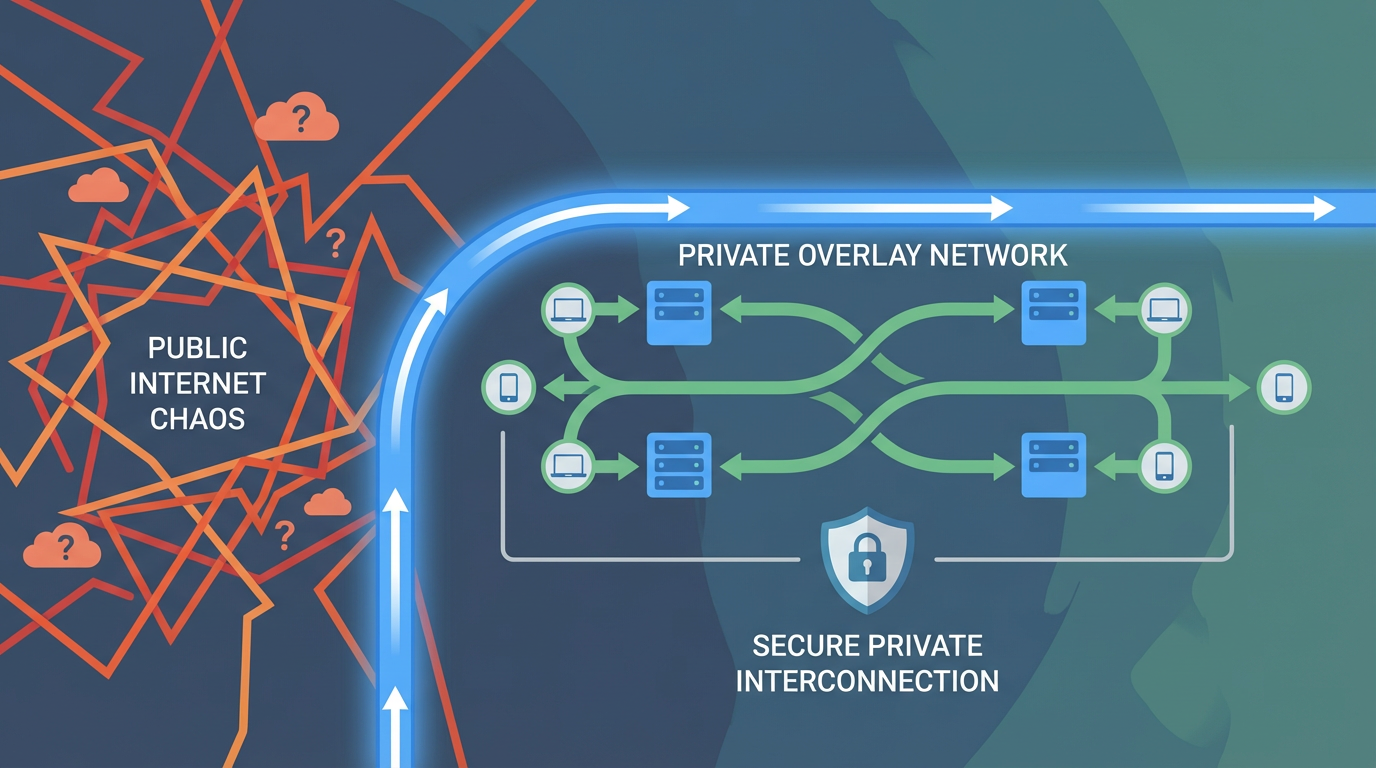
三、总体方案:把运维面迁移到 Overlay 网络
我选择用 Tailscale 做内网(当然你也可以是 ZeroTier、Nebula、WireGuard mesh……工具不同,但思路一样)。
核心变化:
• 服务器之间、我的电脑和服务器之间,通过 100.x 的 overlay 网络互通
• 运维端口(SSH/RDP)不再对公网开放
• 公网只保留“业务需要的端口”(比如站点、代理、API),运维端口默认不属于业务
这样做的好处非常直接:攻击面从“所有互联网”收缩成“我的 tailnet 成员”。
四、Linux VPS 上车:先让它进内网,再谈加固
一个重要的顺序:
先加入内网,再做收口。否则你很容易把自己锁在门外。
我实际执行时的流程大致是:
• 先用商家给的初始方式(root/密码/临时 key)做 bootstrap
• 让机器加入 tailnet,并获得稳定的 100.x 身份(可打 tag:server 等标签)
• 创建统一运维账号 svc,写入统一密钥
• 再做 SSH hardening:禁 root、禁密码、只允许 svc
• 最后再做网络收口:只允许 100.64.0.0/10 访问 SSH 端口
这一套流程本质上是在保证:你在任何阶段都有可用的回路,不会出现“我把门焊死了但还没装钥匙”。
五、一个容易误判的坑:sshd 监听 ≠ 公网可达
很多人会用 ss/netstat 看 sshd 在不在 0.0.0.0:22 上监听,然后得出“还在监听公网 22,不安全”的结论。
但这里有两个层次:
• 进程监听在哪个地址(应用层)
• 外部是否能连进来(网络层:防火墙/安全组/路由)
更进一步,在 Ubuntu/Debian 上还有一个非常容易踩的坑:systemd 的 ssh.socket(socket activation)。它可能导致你即使在 sshd 配置里指定了只绑定内网地址,依然看到 *:22 的监听。
我的处理方式是:让 SSH 服务彻底按我预期工作——禁用 socket activation,并让 sshd 只绑定 Tailscale IP + loopback。这样即便你误配了防火墙,也不会出现“sshd 本身就在公网接口上等人来连”。
这一步的意义是:把防护做成多层,而不是只依赖一个防火墙规则。
六、 Windows VPS:要想“可运维”,别只装 Tailscale
Windows 加入内网相对容易,但如果你希望后续“让自动化真正跑起来”,你需要一个可以远程执行的入口。
单靠 RDP 不够“可规模化”,因为它天然是 GUI 的、手工的。
我的做法是:
• 让 Windows 加入 tailnet(获得 100.x 地址,打上 tag:server / tag:edge)
• 开启一个可远程执行的通道(例如 OpenSSH Server 或 WinRM)
• 再用 Windows 防火墙收口:至少保证“SSH 只允许从 Tailscale 网段访问”(RDP 是否收口看需求)
结果是:Windows 也可以像 Linux 一样被纳入统一运维体系,GUI 只在“确实需要点按钮”时才用。
七、Tags / ACL:先可用,再收敛
我会给机器打上 tag:server 作为统一身份,再按角色加 tag:edge/tag:app/tag:transit。
ACL 的策略我倾向于“先宽后紧”:
• 起步阶段:保证自己不会被锁、保证管理效率
• 稳定后:把权限从 “members” 收到 “admin” 或 jumpbox
• 当 tailnet 引入更多设备/成员时,才需要更精细地做分区和最小权限
这不是“安全不重要”,而是先把运维体系搭起来,才能持续地安全。安全如果不可持续,最终会被人(包括未来的你)绕过。
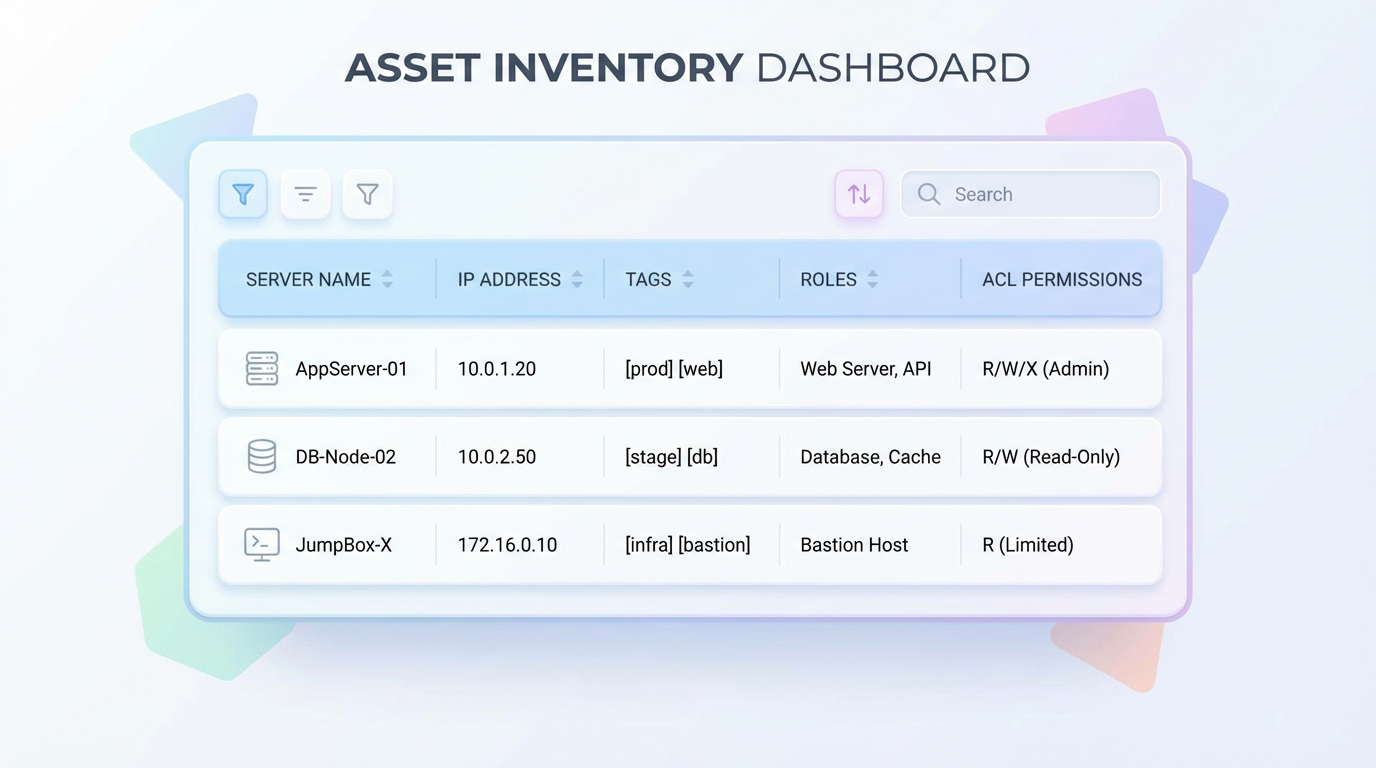
八、资产清单:让“事实”可查询、可审计
我把所有 VPS 维护成一份资产清单(例如 YAML),它不是为了“记录 IP”,而是为了:
• 任何时候都能回答:这台是什么、用途是什么、在哪、怎么进
• 变更有迹可循(新增、下线、角色变更)
• 自动化有输入来源(批量巡检/批量加固)
以及一个非常重要的原则:不要把密码、私钥写进清单。资产表应该是“可公开的结构信息”,秘密应该在更安全的地方管理。
九、收益:把运维变成一种“低心智负担”的状态
收口到内网之后,最大的收益不是“更安全”,而是:
• 我不用每天担心“是不是哪台又忘了关”
• 我可以更大胆地做自动化,因为入口/权限/路径一致
• 我的安全是“默认值”,不是“要靠记忆维持的状态”
当你拥有十几台、几十台 VPS 时,这种收益会成倍放大。